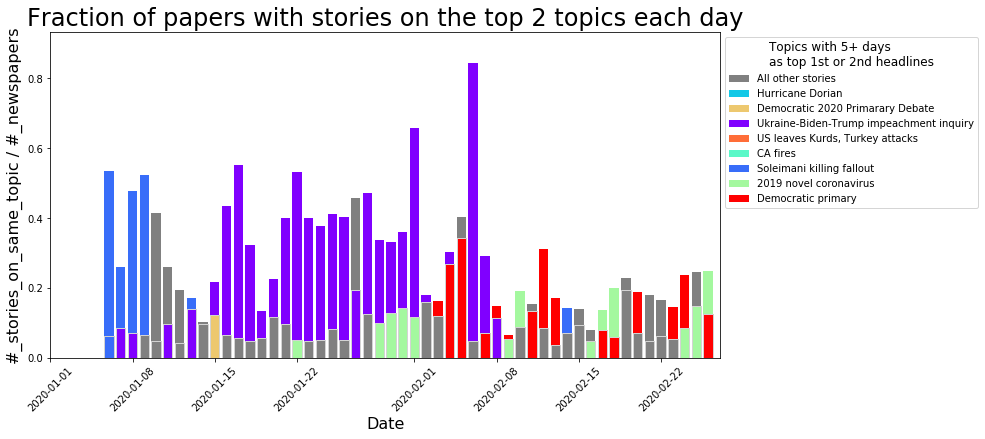
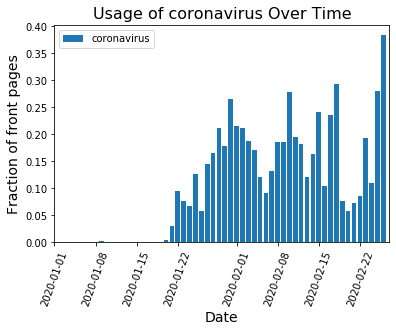
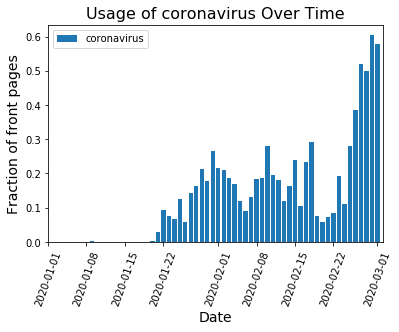
When the game changes depends on how seriously we take the disease.
This week Moderna Inc. and Pfizer both announced their COVID-19 vaccines were 95% effective.Those are amazing numbers and could eventually end the global pandemic.
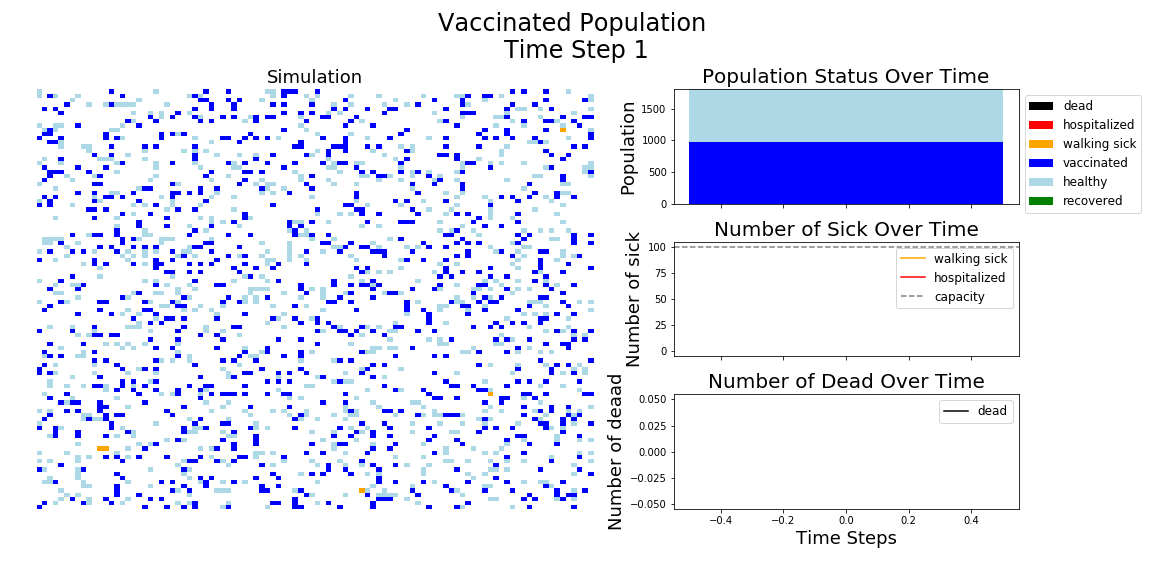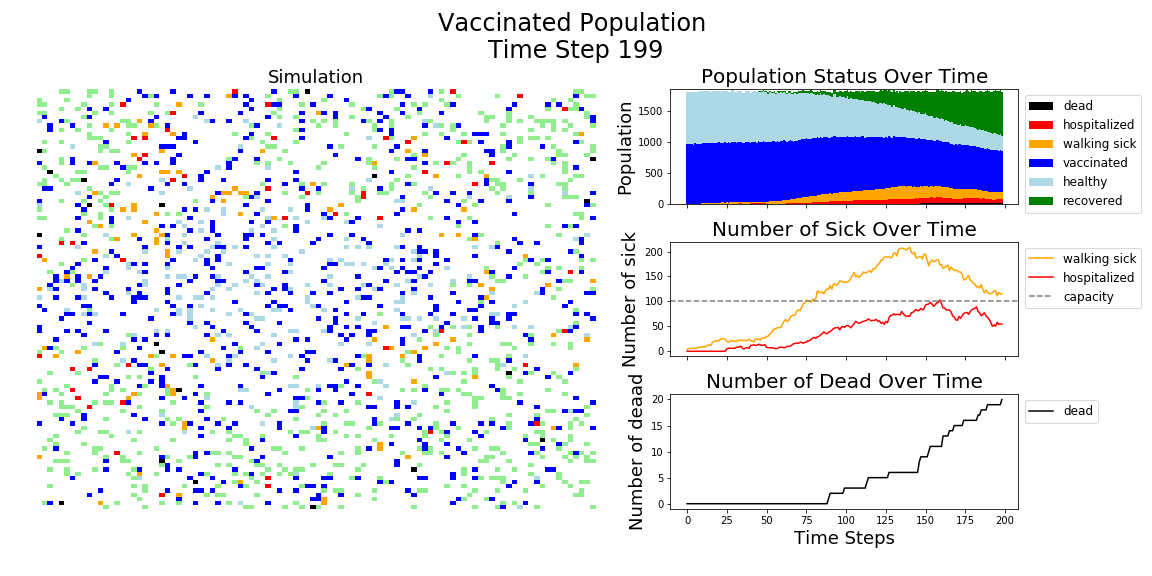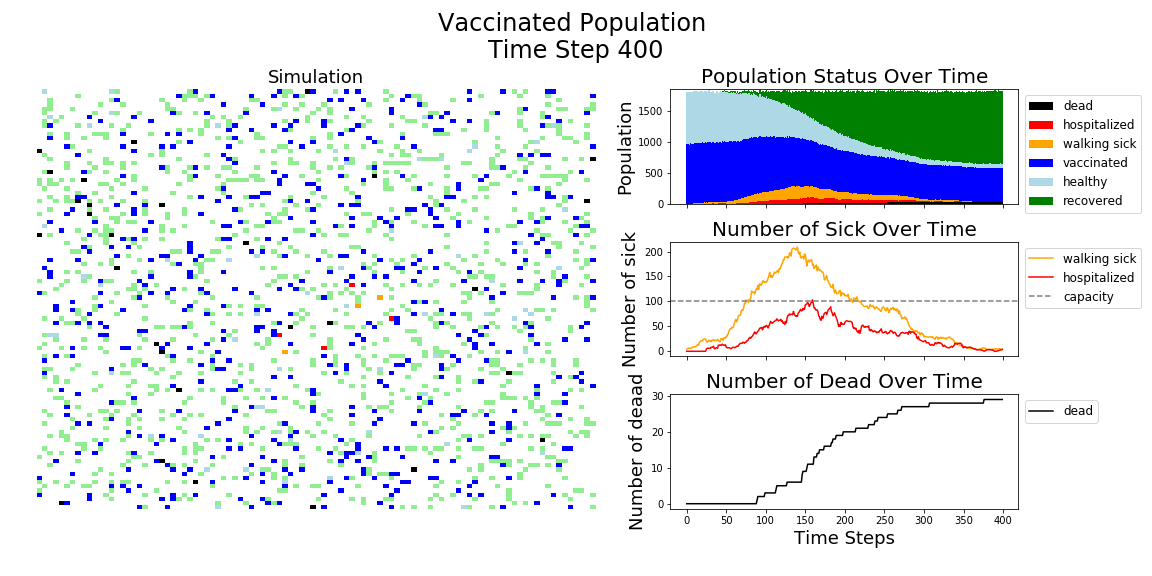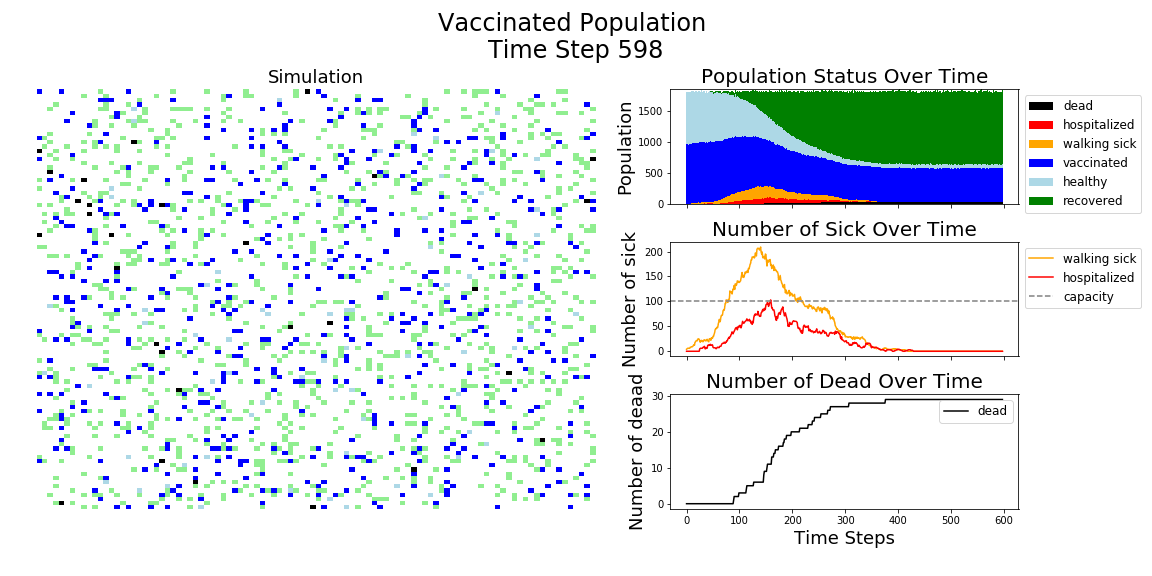
The most recent polling suggests 58% of Americans would consider getting the COVID-19 vaccine. Here’s an Agent Based Model (ABM) showing just how much of an impact a 95% effective vaccine would have on a population with 58% vaccinated.


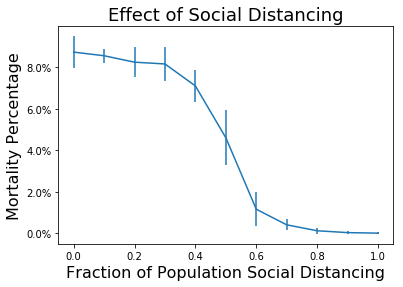
So, a huge effect. Sadly, that won’t happen any time soon. Moderna thinks they will have 20 million doses of vaccine available by the end of 2020. If that was distributed by lottery, that would mean only about 5% of each community would be vaccinated. Hopefully we will be more clever about the distribution, but it will still be many months until enough people are vaccinated to have a strong impact. In the mean time, it is vital to keep up the mask wearing and the social distancing! To see why, let’s look at the impact prevention measures like social distancing, mask wearing, and vaccinations can have on the start of an outbreak.

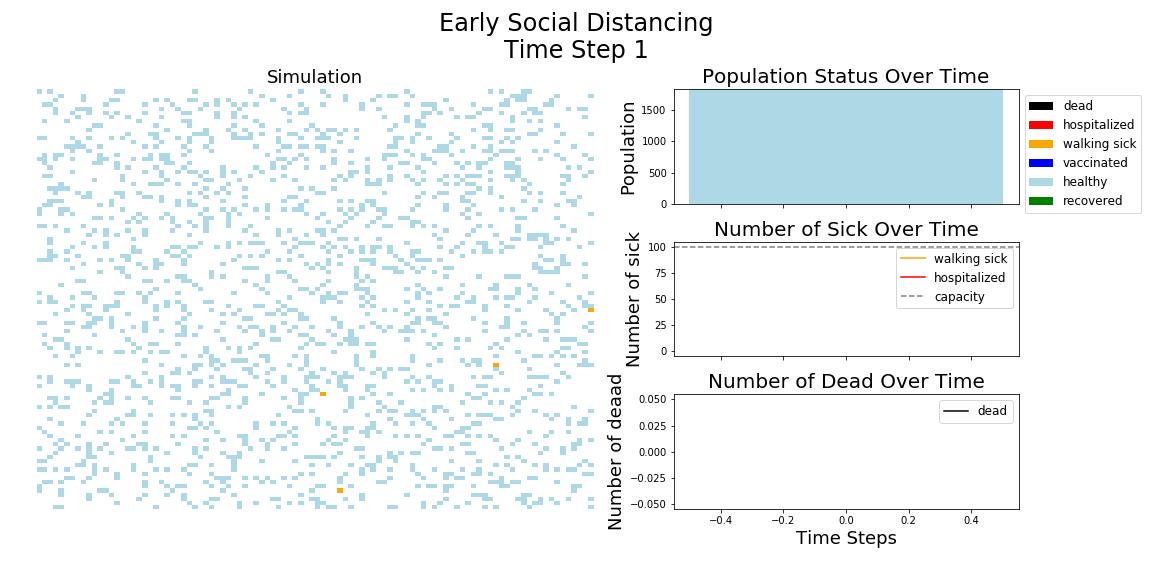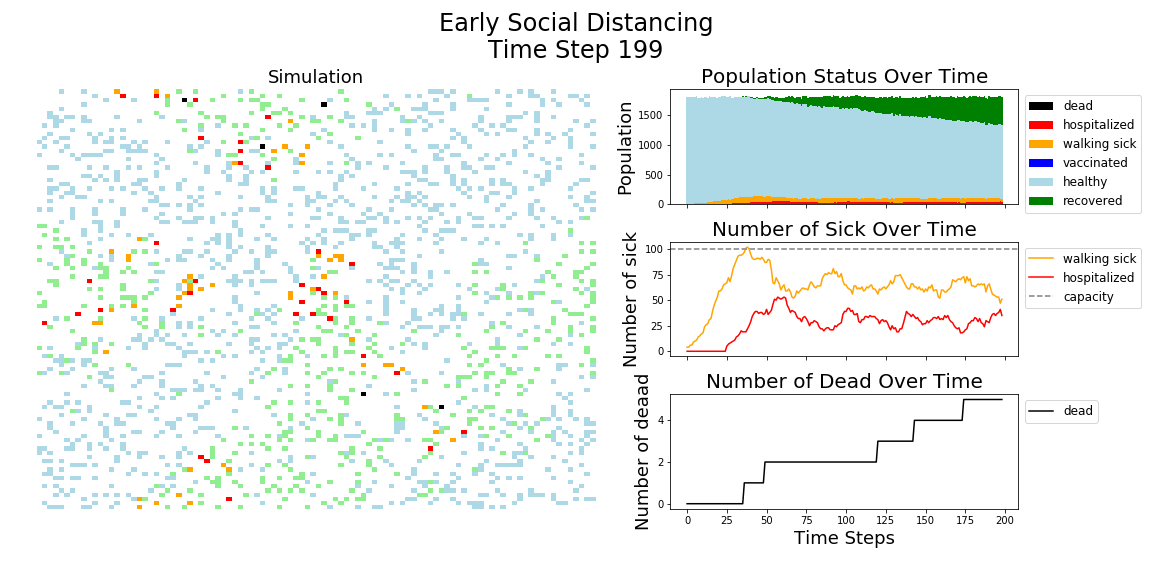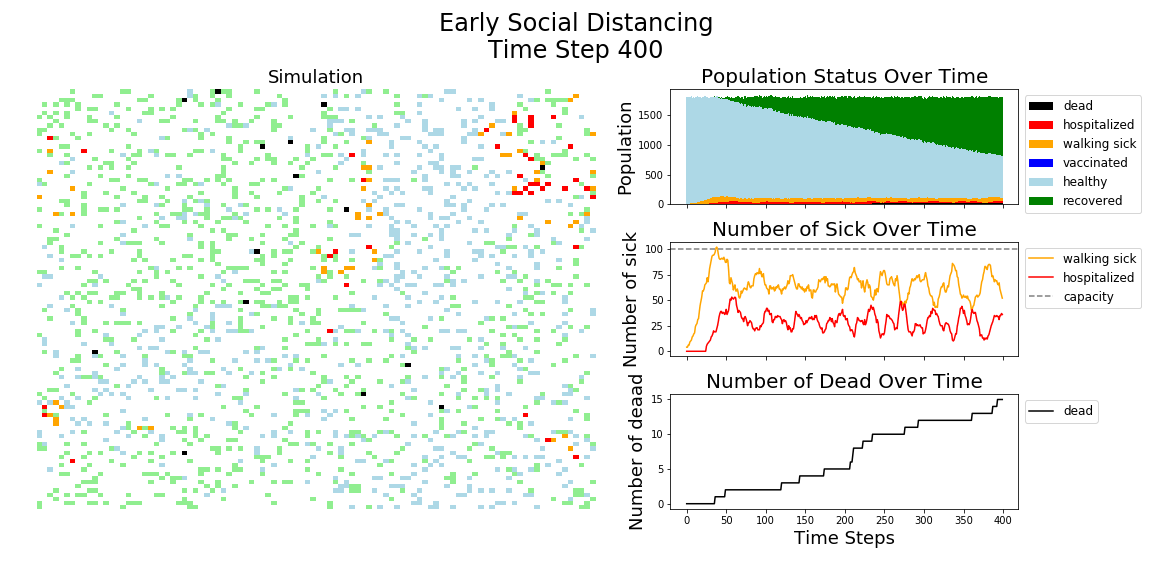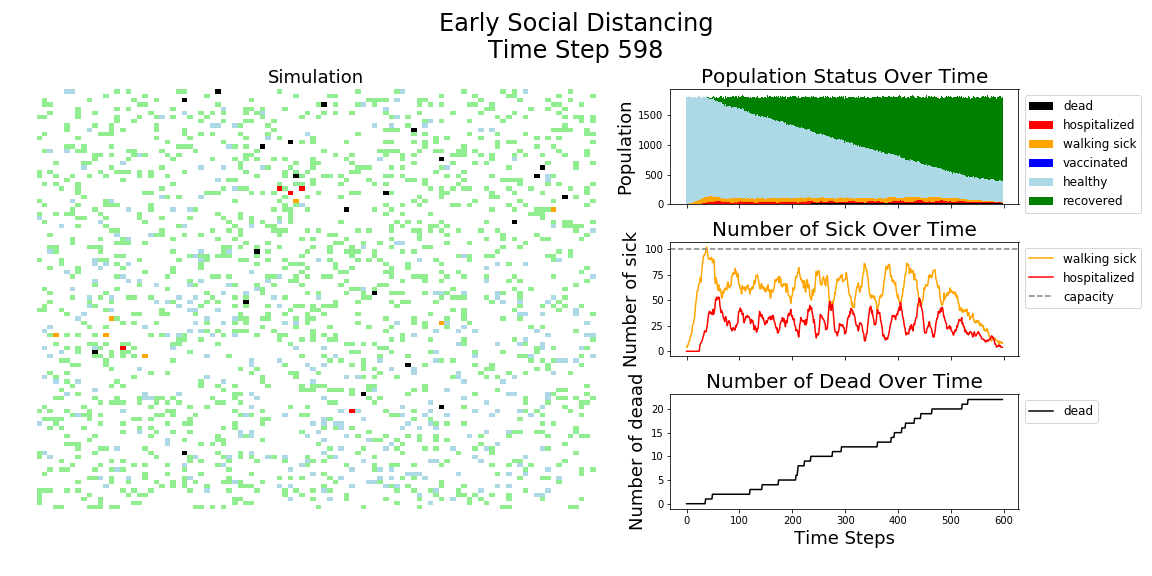
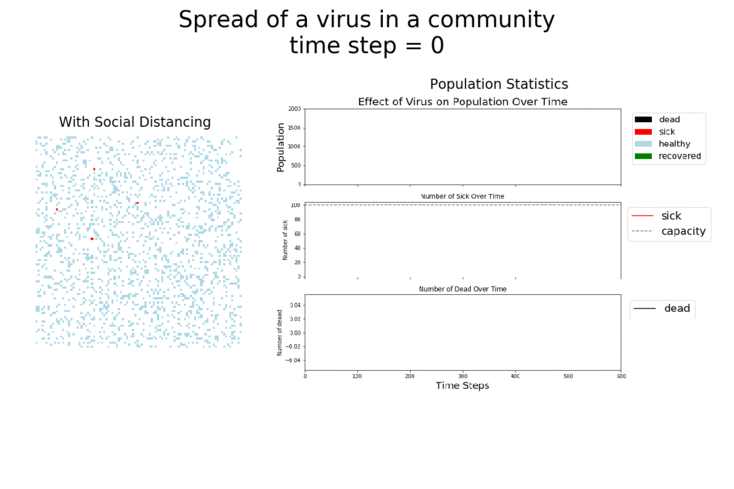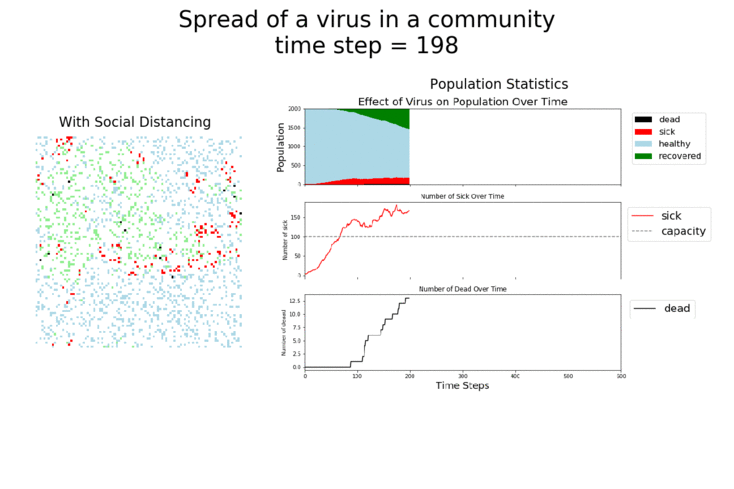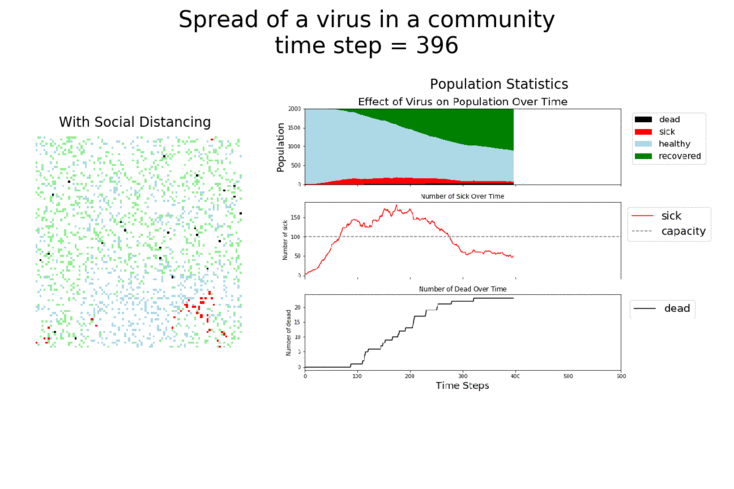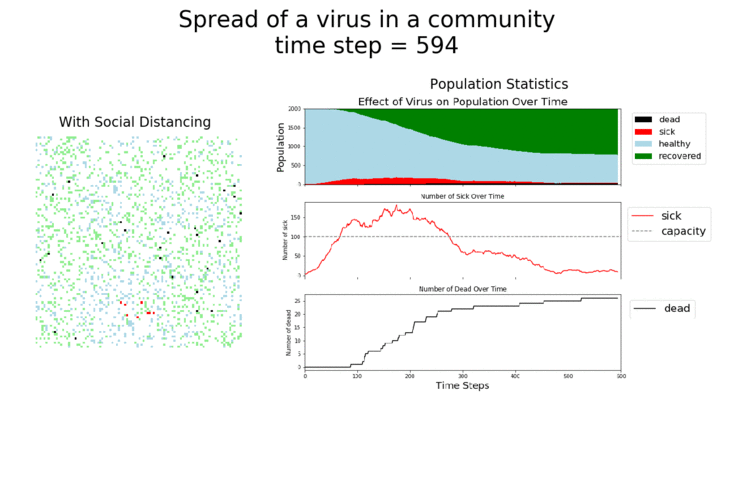
In each of the above simulations, 1,200 agents go about their little agent lives under different sets of conditions.
- If the agents are taking COVID-19 seriously, a good chunk of them are wearing masks (50%) and the community is trying to do basic social distance (10% movement reduction).
- If they agents aren’t taking COVID-19 seriously, no one is wearing masks and movement is unrestricted.
- With the vaccine, I’m assuming 20% are vaccinated, nearly quadruple what Moderna thinks they can supply by the end of 2020. It’s enough to see an effect, but also a more realistic short term expectation, versus the 58% of Americans who say they would take the vaccine.
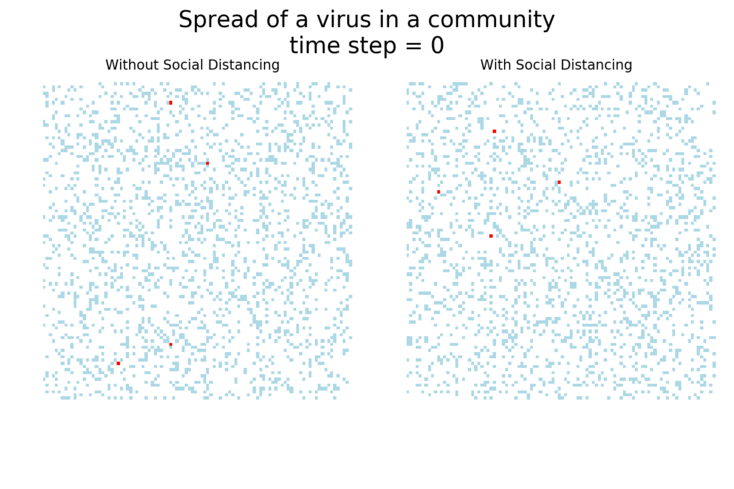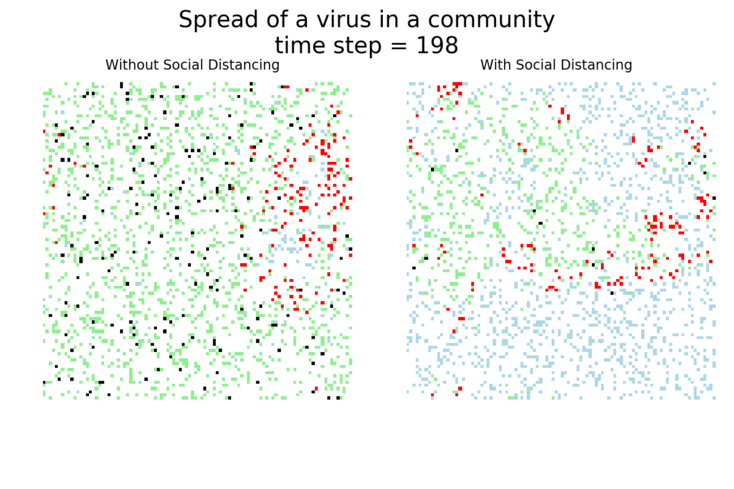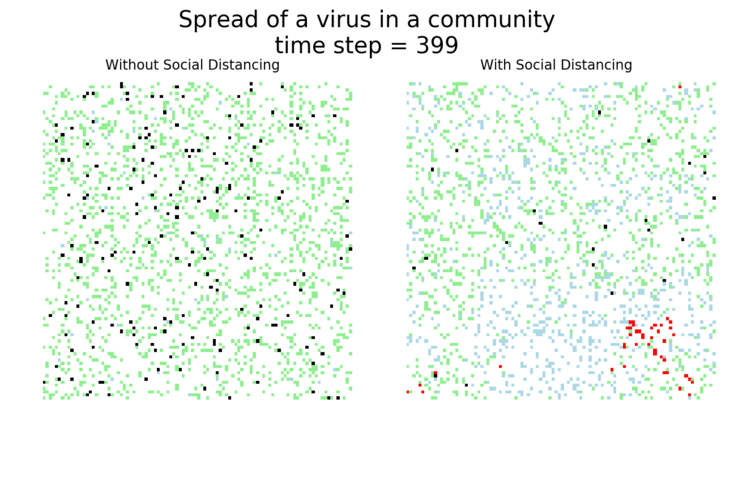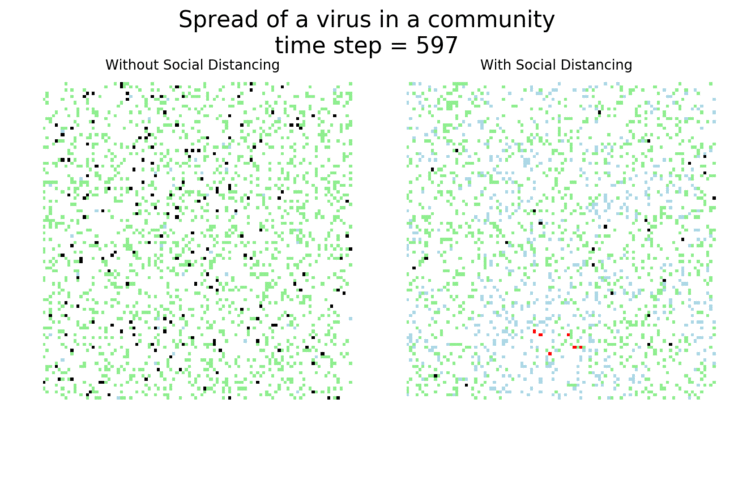
The main takeaway should be pretty clear: disease spreads fast when people don’t take it seriously. The vaccine can help slow that spread, but only a combination of vaccines and other actions can really stop the disease.
In the above gif, I’m only showing the first 100 time steps. That’s far fewer than shown in the first few images of this post. That’s to avoid getting to saturation issues in this work. I’m simulating only 1,200 agents, and the community can pretty quickly saturate on disease spread. Only about 12 million cases of COVID-19 have been reported in the United States, which is about 3.6% of the country’s population. We are far from seeing herd immunity effects in real life, and I wanted to avoid showing them in these visuals.
I’ve used ABMs to model the spread of COVID-19 in communities before, focusing on how key social distancing and movement reduction were to flattening the curve and slowing the spread of the disease. It’s worth saying again that these are simplified models. They help give us insight into the real world, but don’t take they numbers they generate as absolute truth!
Here are some sand plots of those same simulations from above. They drive home how many Agents get sick with the disease in each scenario. As you can see, the combination of vaccines and taking the disease seriously makes the biggest impact.

It should be very clear that growth rates are highest when masks are not being used and social distancing has gone out the window. If those are used, the vaccine does provide a bit of help, but it’s not as big of an impact as the other measures.
It may surprise you, but you don’t actually need a vaccine to drive COVID-19 out of a community. With high enough mask wearing or social distancing, the curve can be kept flat indefinitely:


We saw that in the spring, when people were really staying home. Measures of mobility across the country showed a huge drop in travel and the number of new cases of COVID-19 in the country dropped. However, the costs of social distancing proved to be too much for us, and by the summer mobility had really picked back up.


The appetite for long term mobility reduction seems to have gone away, although some place that were hit hard early are still being more cautious than before the pandemic set in.


Mask wearing can also really help. Studies have found masks are up to 67% effective at preventing COVID-19 transmission for each interaction. With enough people wearing masks, you actually don’t need very much social distancing (in these ABM models) to really reduce the spread of the disease.

Look at that. If we had just moderate social distancing and good mask wearing, we would hardly even need a vaccine. Unfortunately, mask wearing started to increase from the 20% range to the 50% range in the summer, right when social distancing efforts were winding down.
And unfortunately, the United States seems stuck at around 50% mask wearing for some reason. Some don’t want to wear it for political reasons. Others don’t want to be a bit uncomfortable. Still others like to have their noses in the open air. For whatever reason, we can’t count on enough people wearing masks to stop the spread of COVID-19.
The hope now is that we can get just enough of the county vaccinated while also maintaining just enough social distancing and have enough people continue to wear their masks to actually stop the disease. But a big worry of mine is that we will hear about a vaccine in our area and stop doing the other things. Stopping the mask wearing and social distancing before enough people are vaccinated is a recipe for one final, tragic COVID-19 surge. One that could be entirely prevented with maintained vigilance.
So do your part! Keep wearing masks and keep socially distancing as much as you can. We may finally have a light at the end of the tunnel, but a whole world of hurt could happen before we get there. It’s up to all of us to stop as much of that pain as possible.
Code for this work can be found on GitHub.
As always, this blog represents my personal views and is not affiliated with any government or organization.









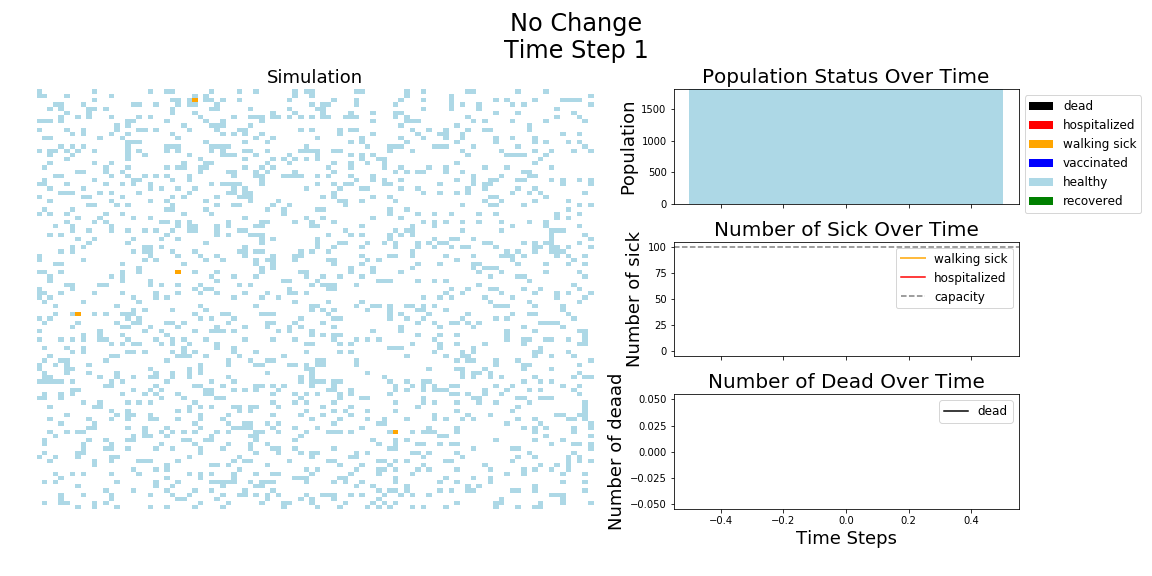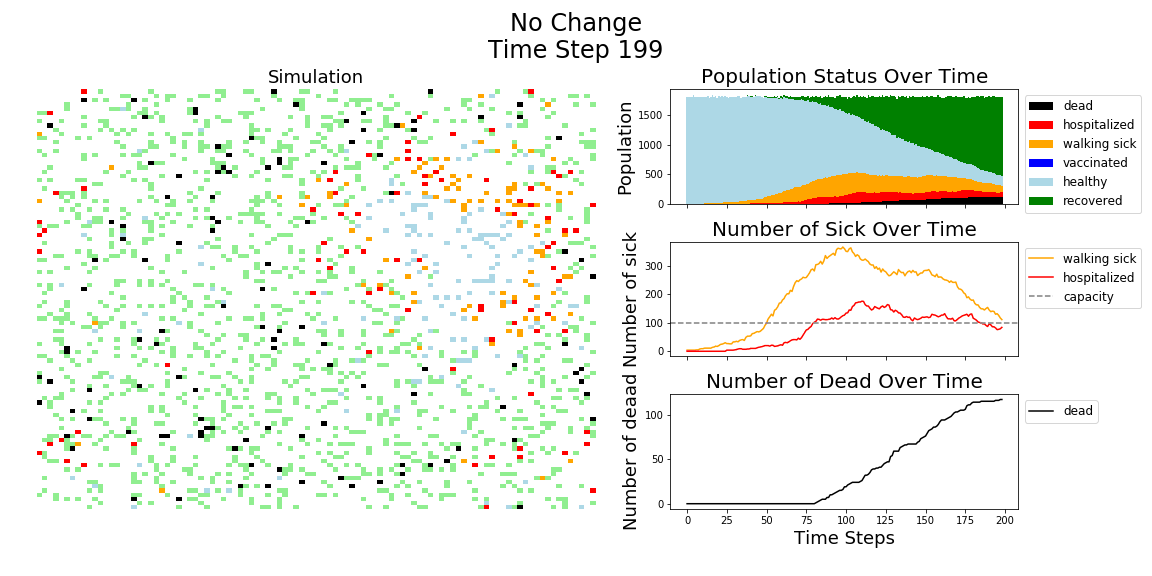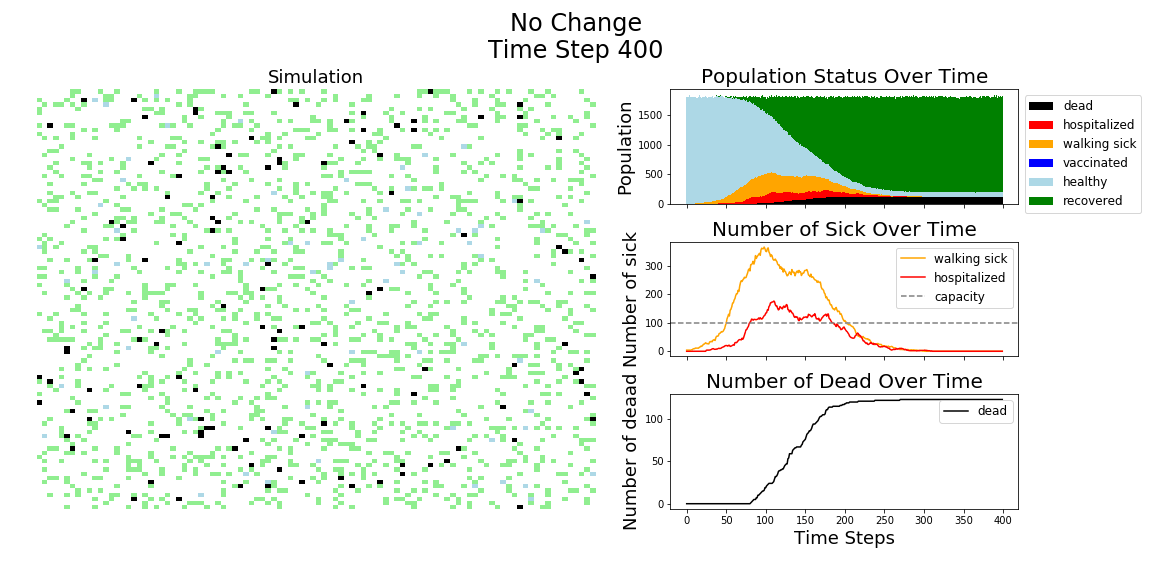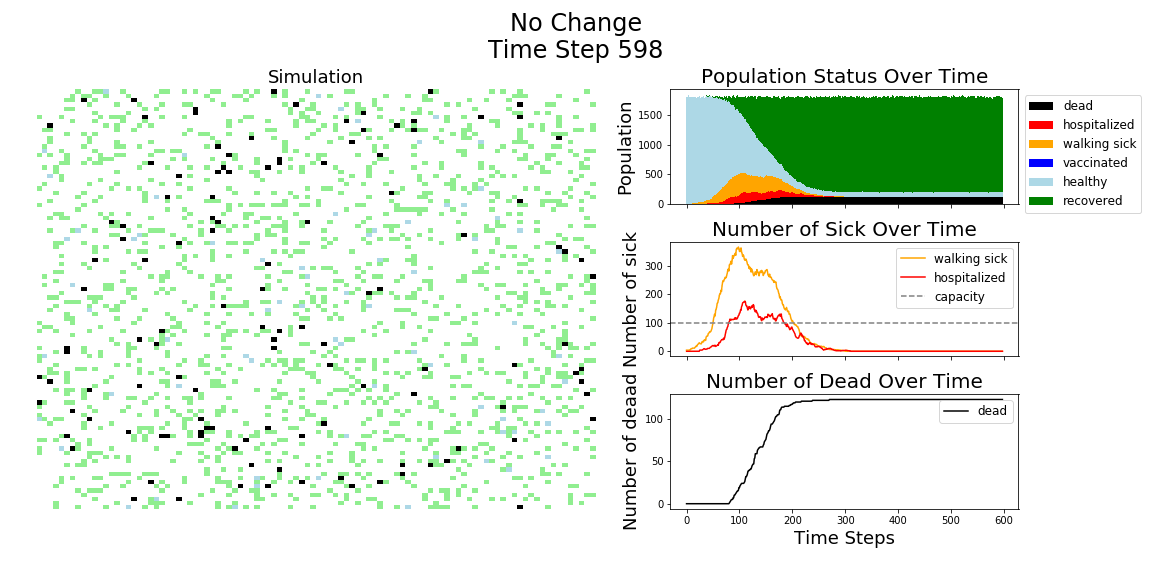
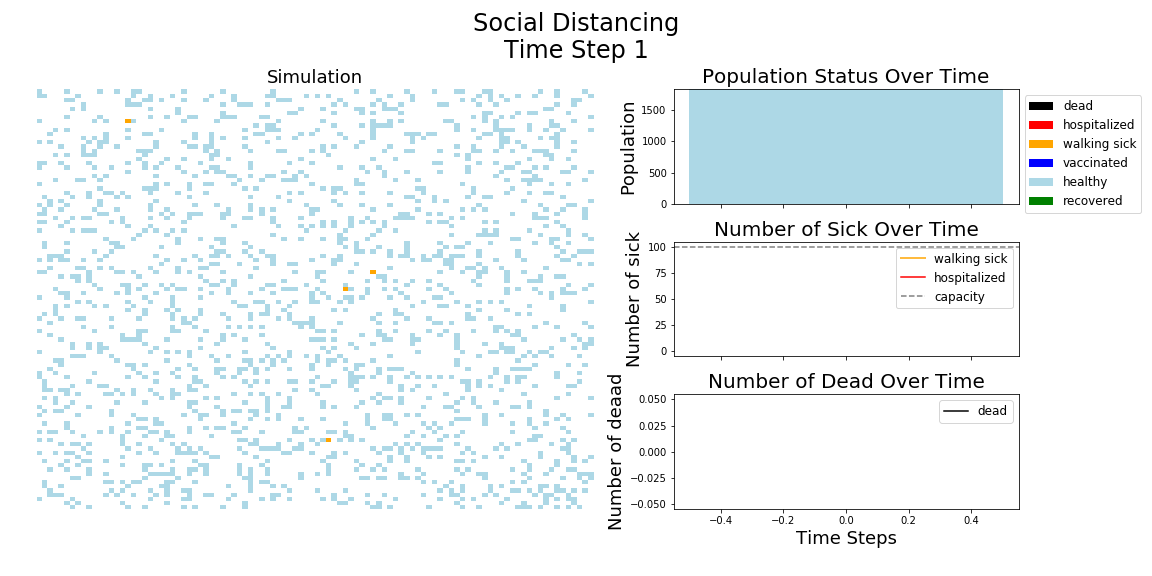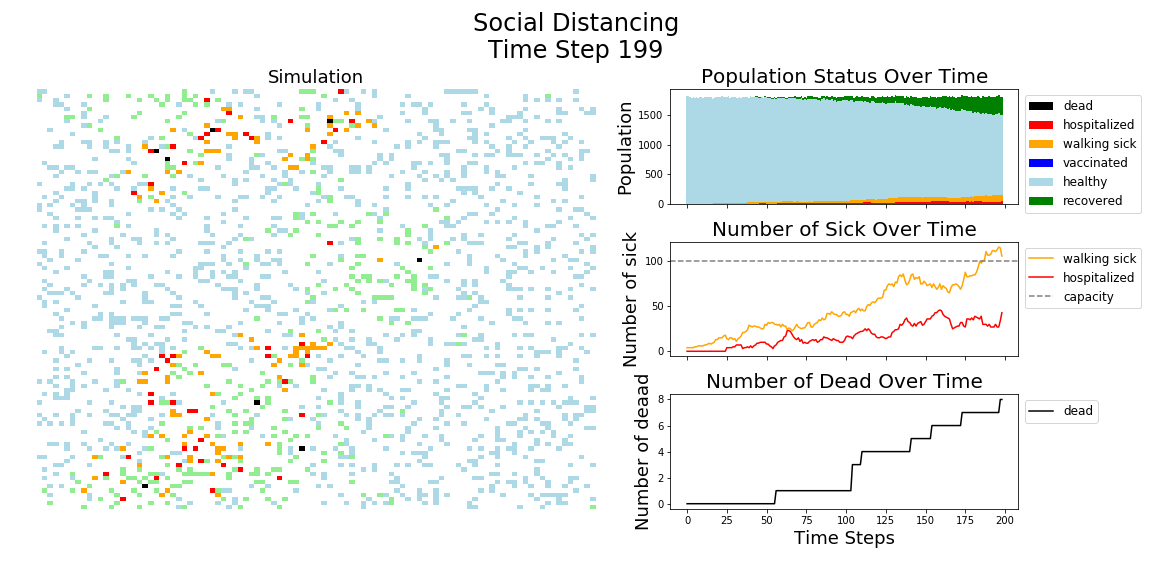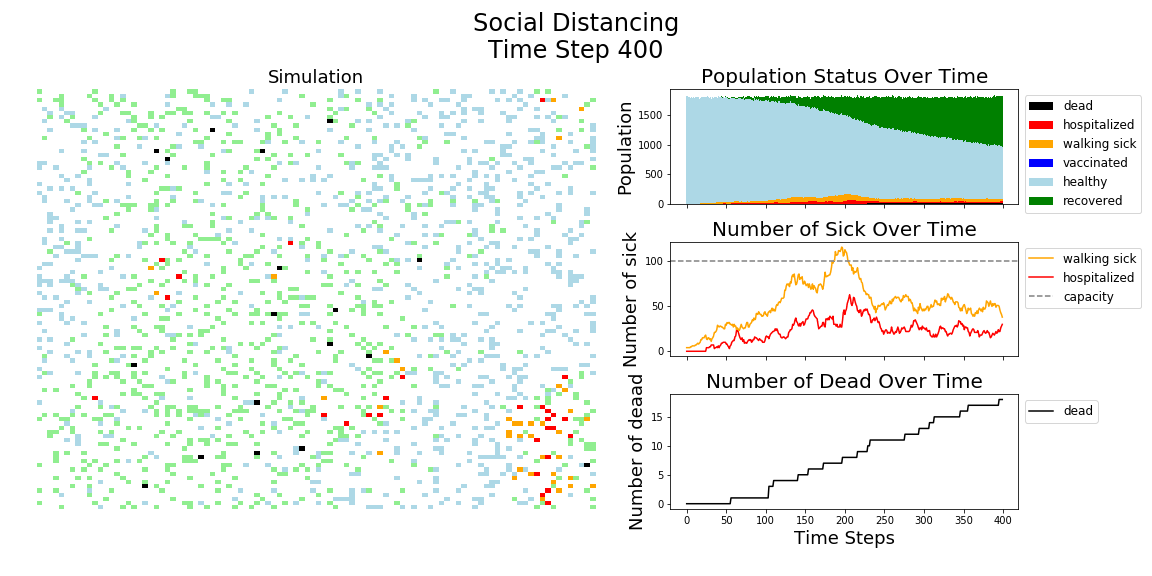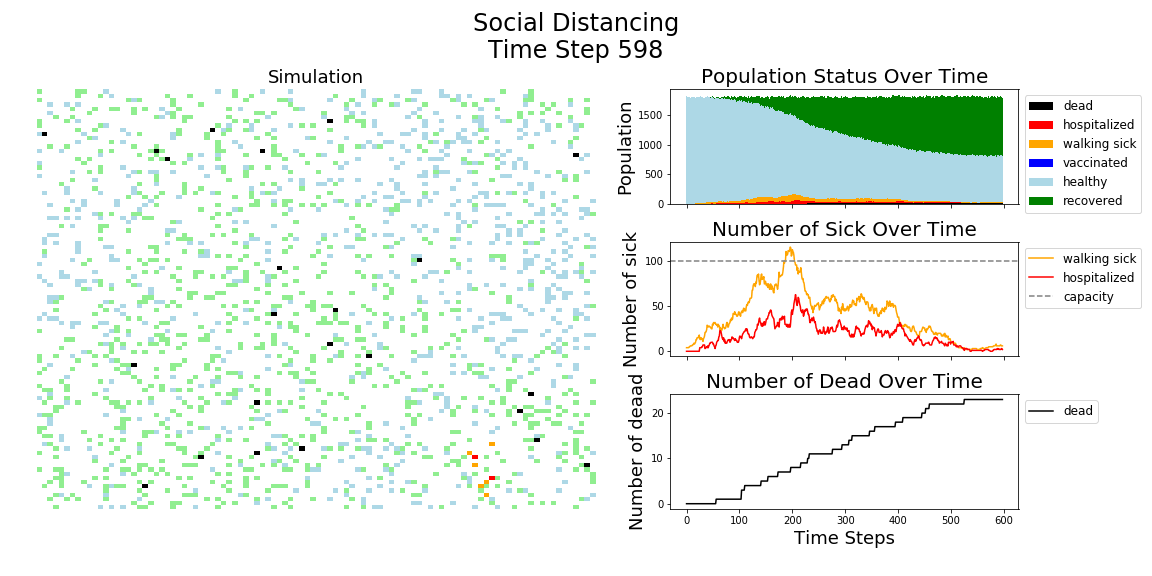
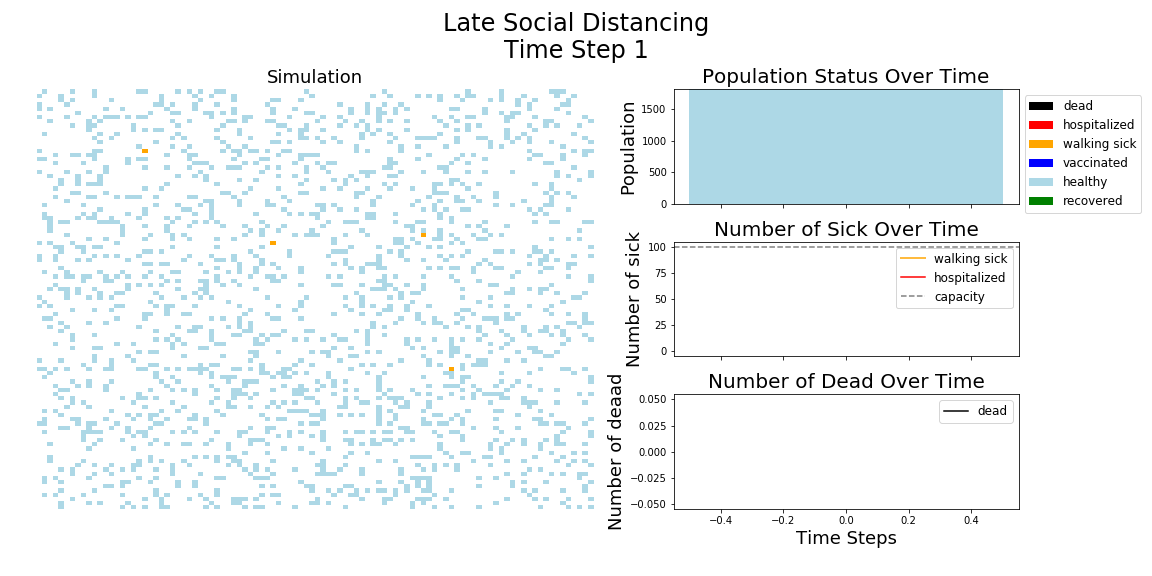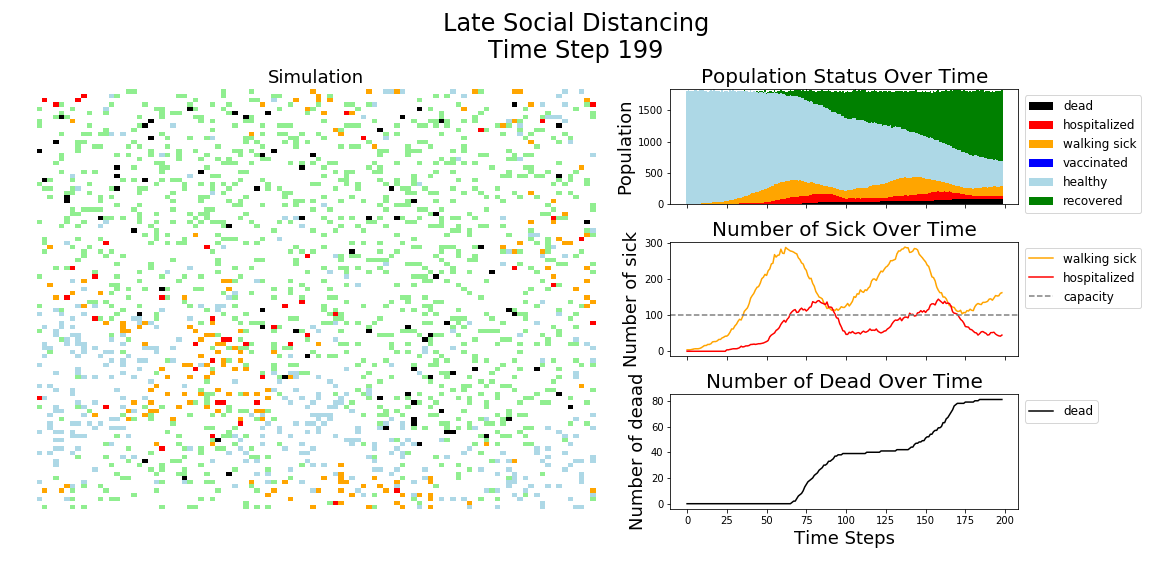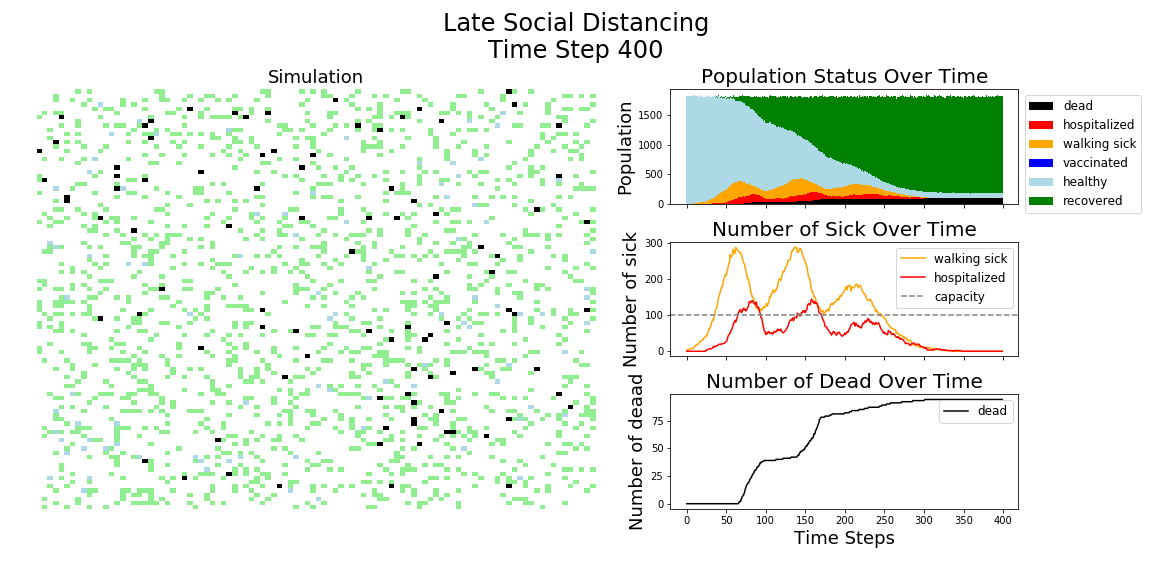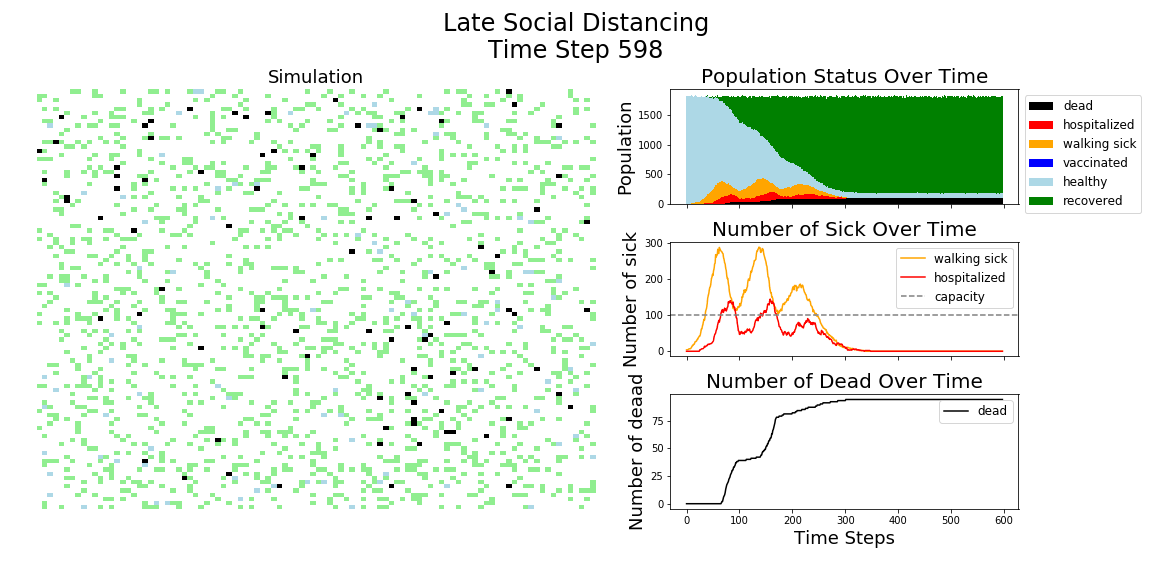










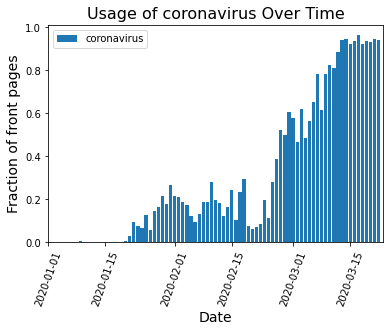



 The model has the following features:
The model has the following features: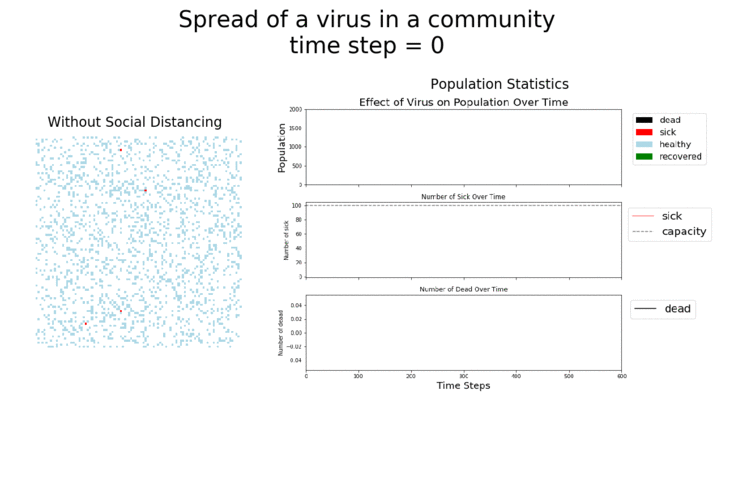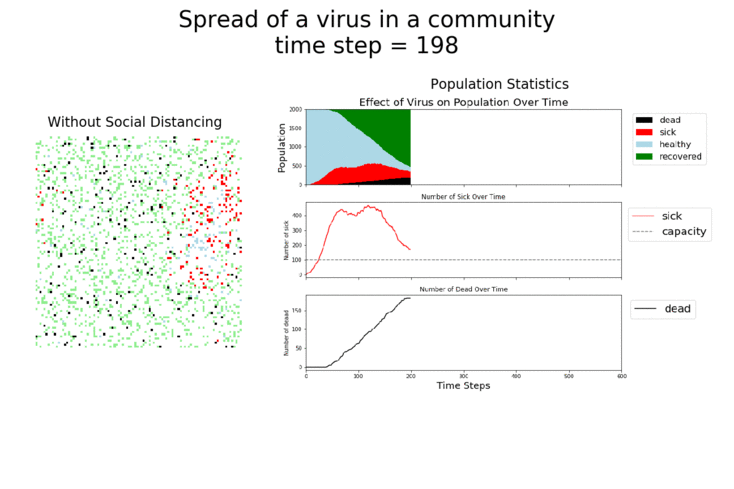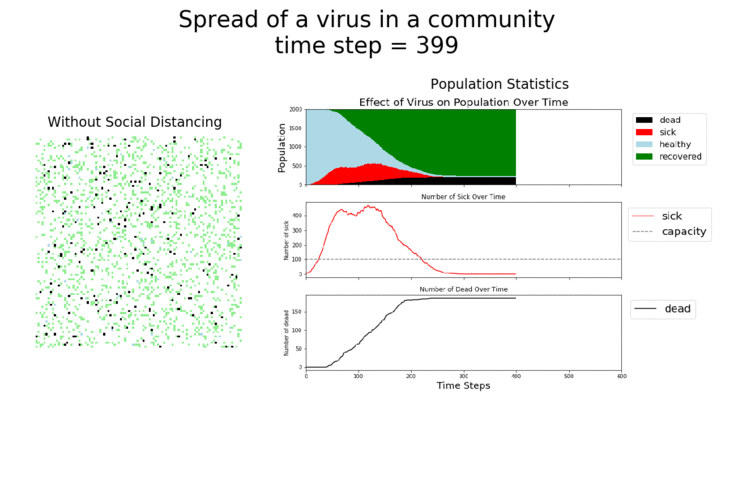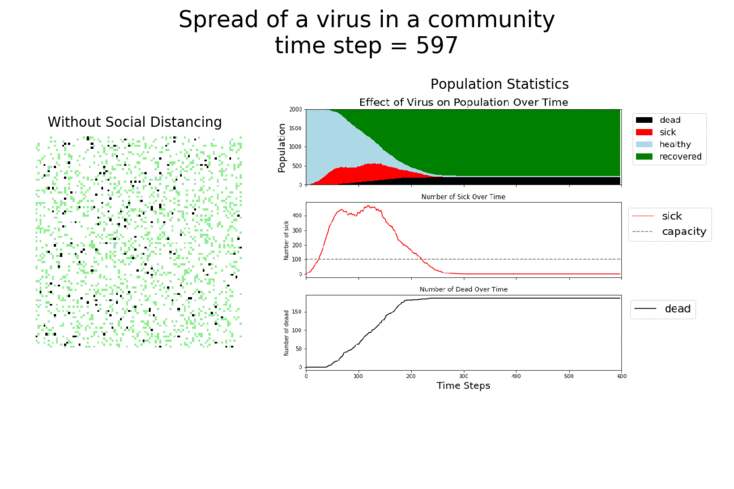


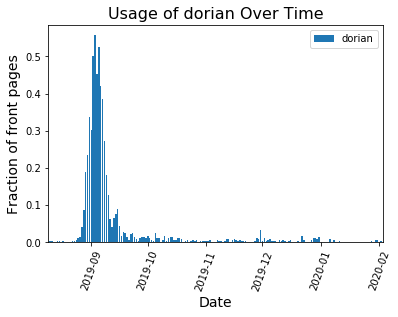
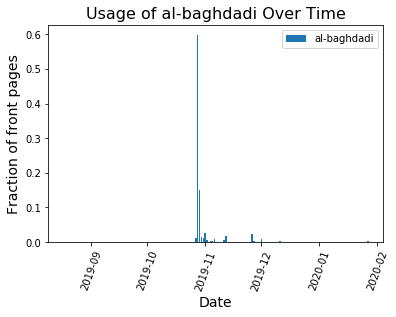
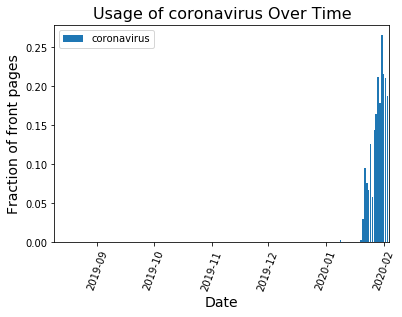
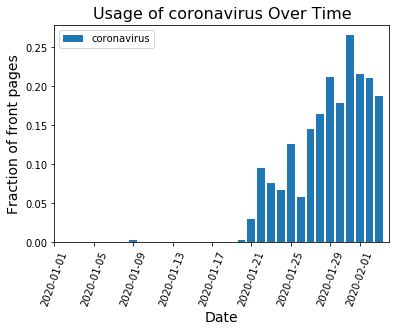
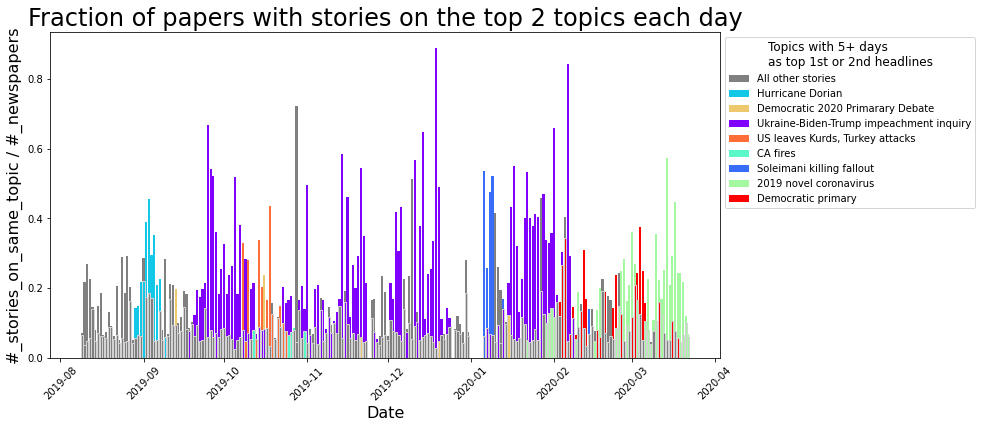
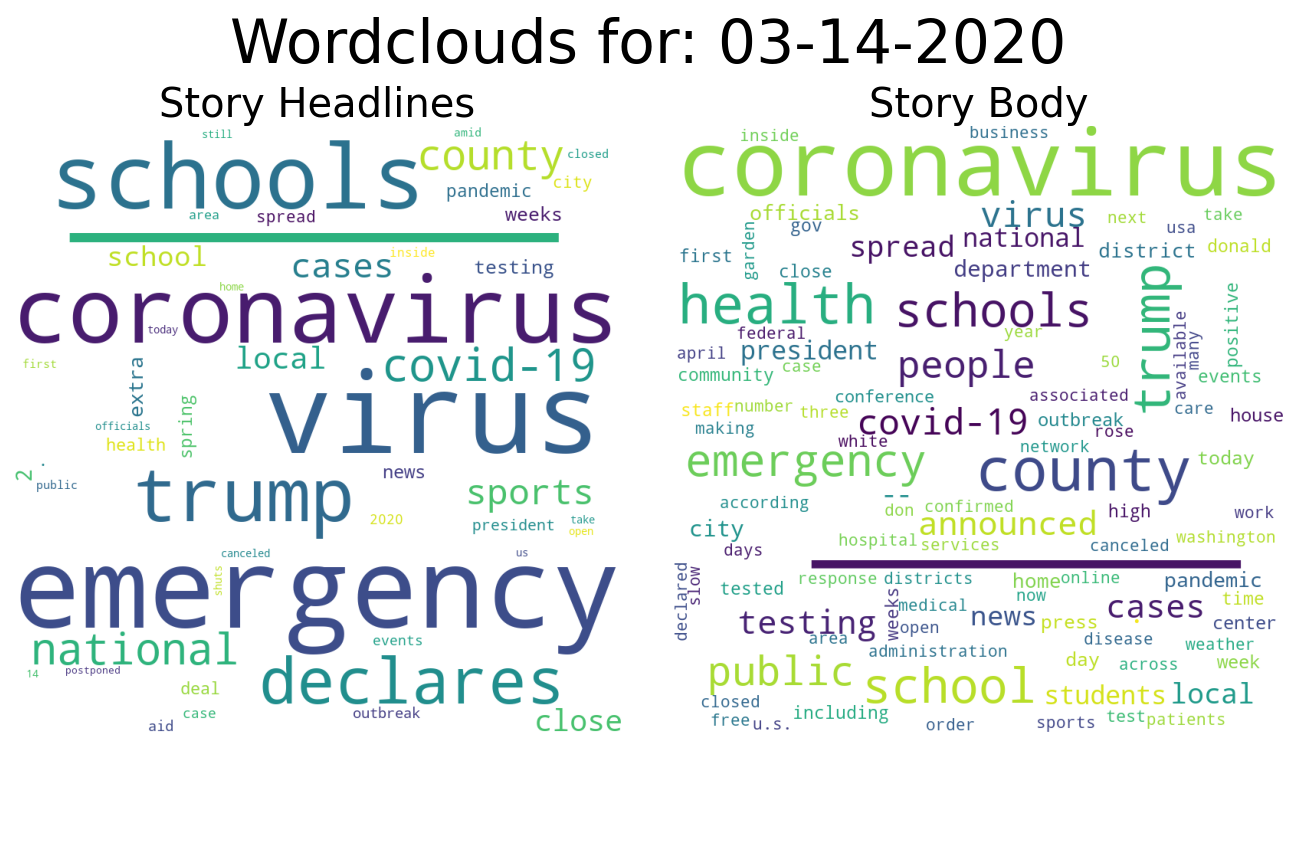 When there isn’t a strong national story dominating the headlines, word choice is spread out over many topics and no word frequencies get particularly large. That’s what we see on days like Feb. 23:
When there isn’t a strong national story dominating the headlines, word choice is spread out over many topics and no word frequencies get particularly large. That’s what we see on days like Feb. 23:

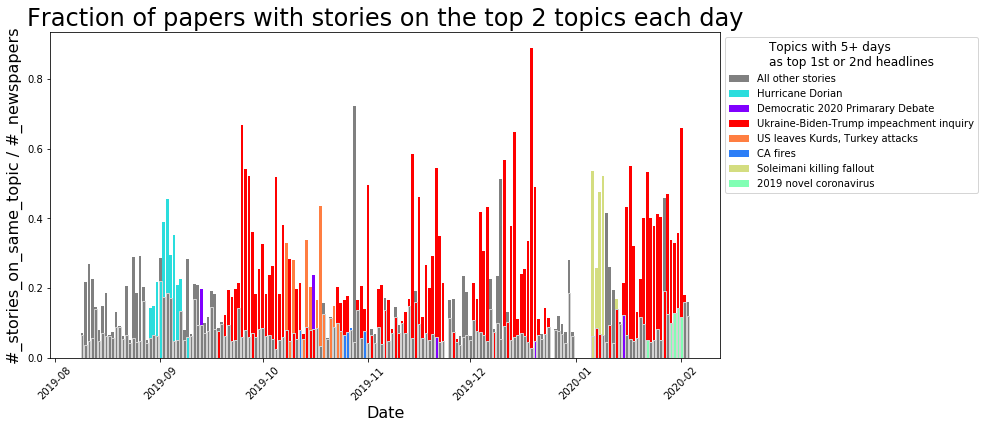
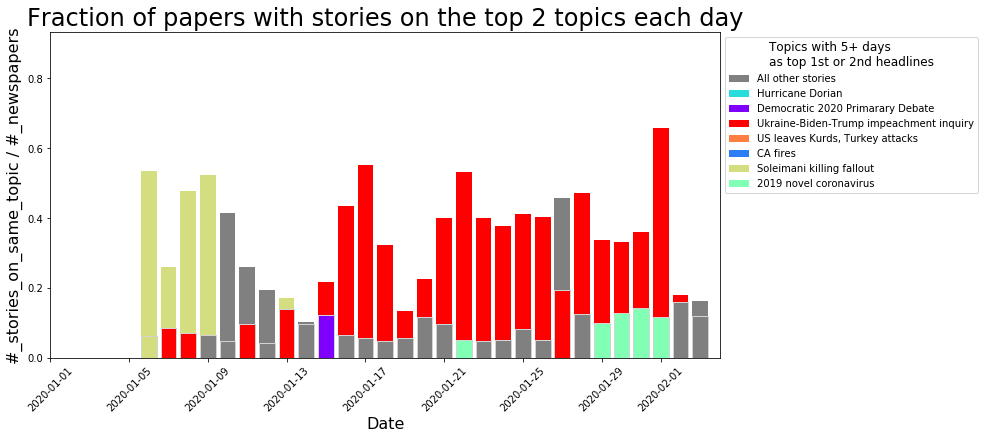
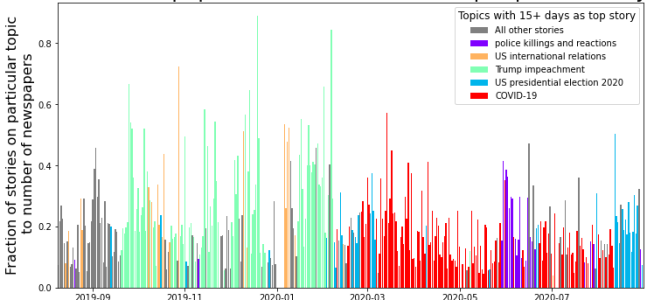
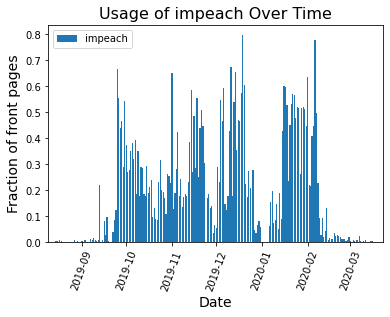
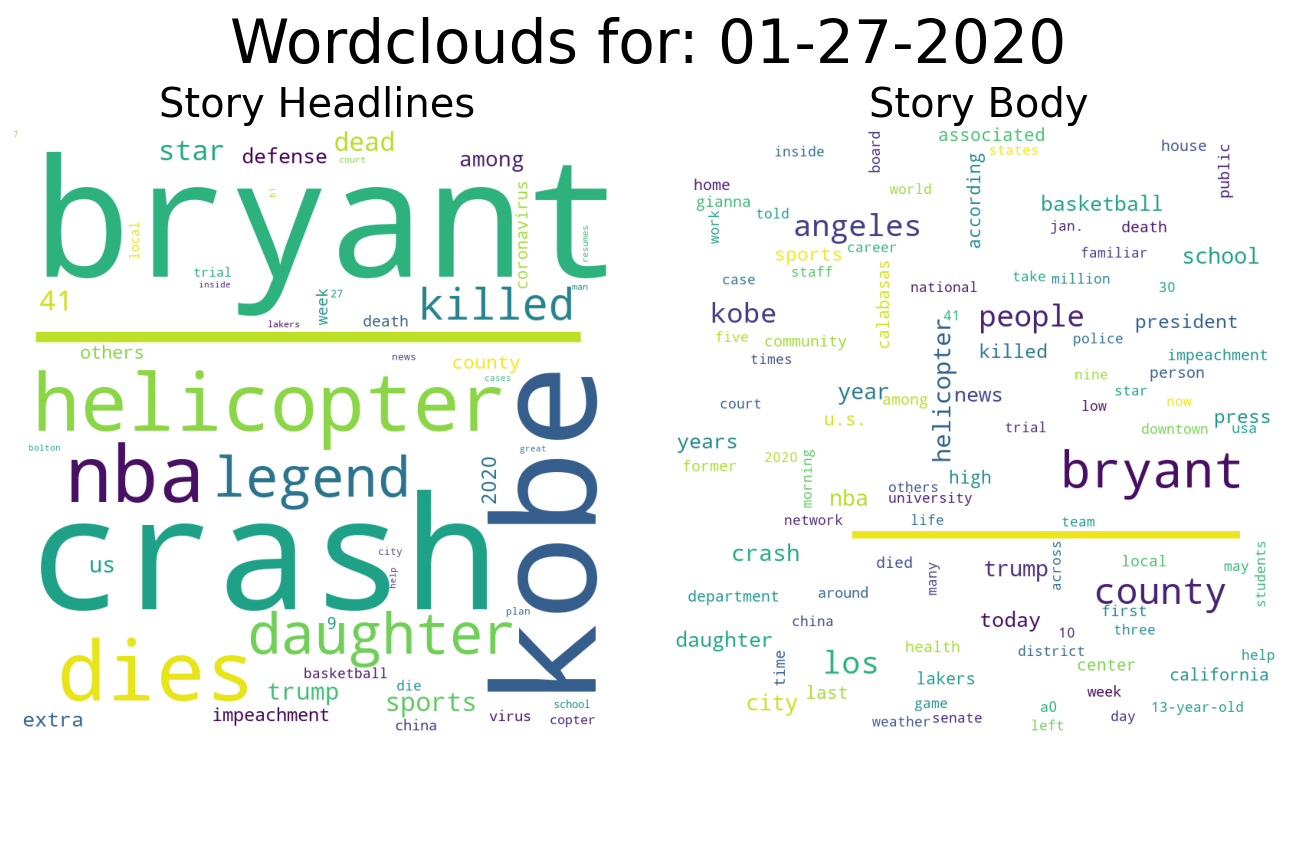 Comparison to the Trump Impeachment Trial:
Comparison to the Trump Impeachment Trial: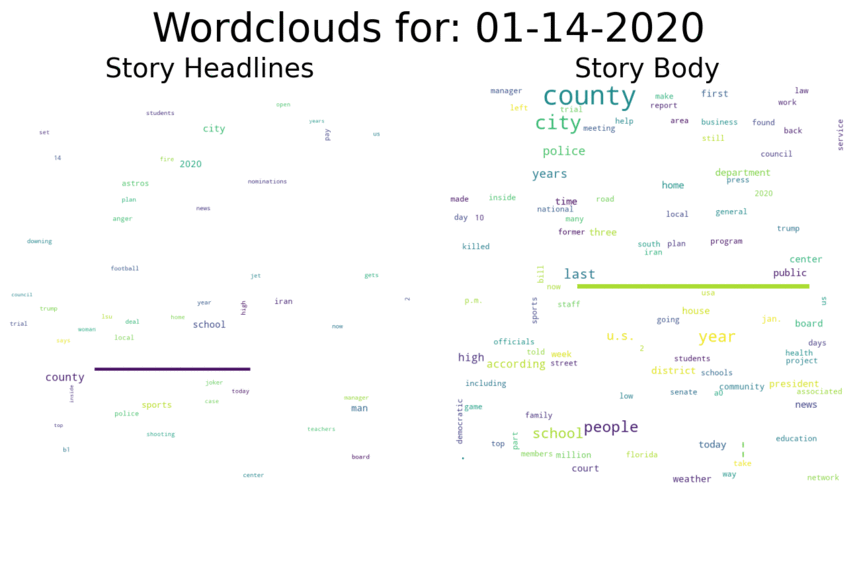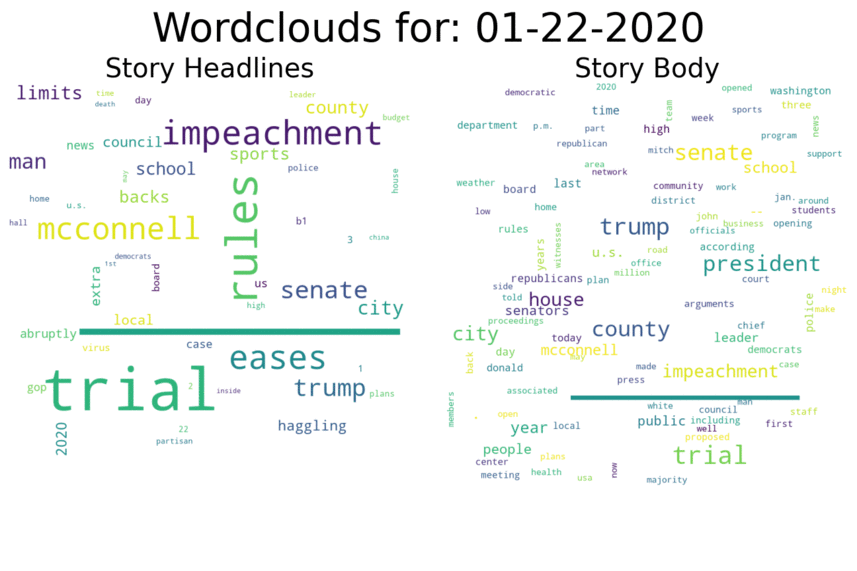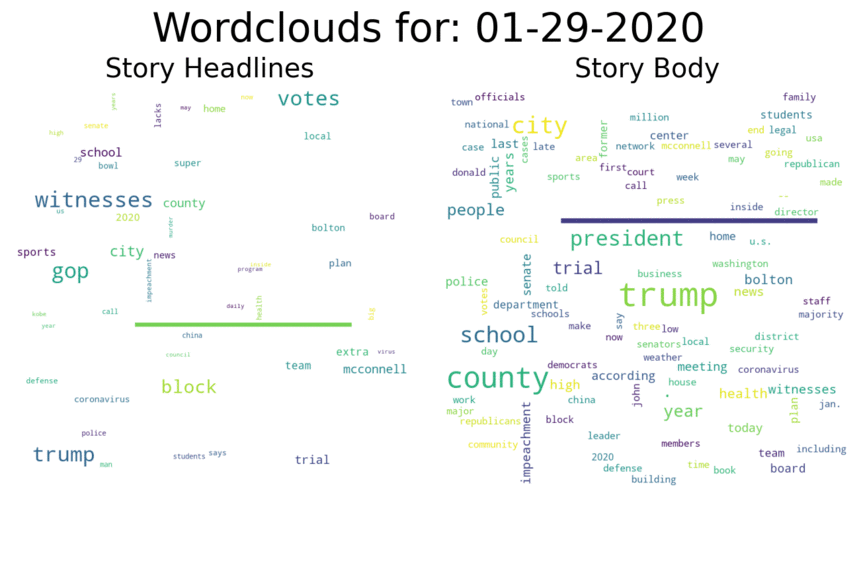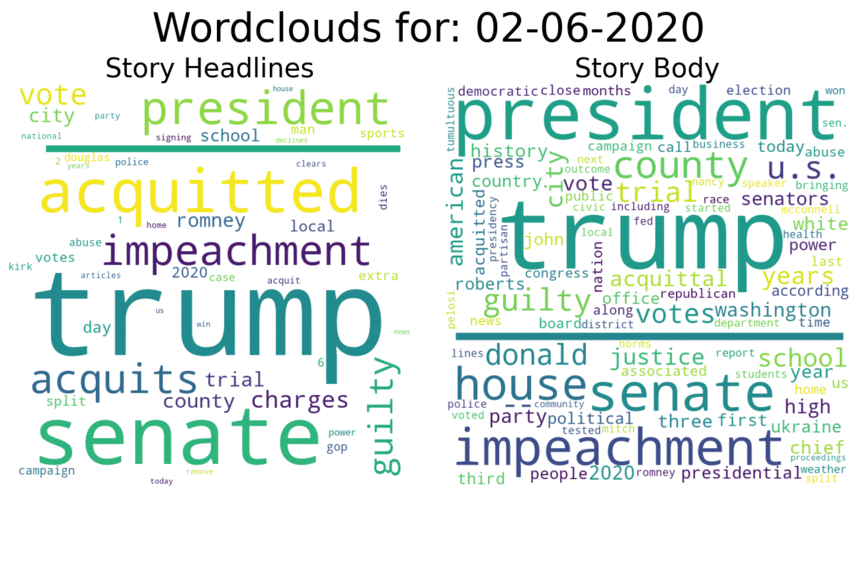 Again, we can see surges in the word cloud at various important points during the trial, with the largest surge occurring after Trump was acquitted:
Again, we can see surges in the word cloud at various important points during the trial, with the largest surge occurring after Trump was acquitted: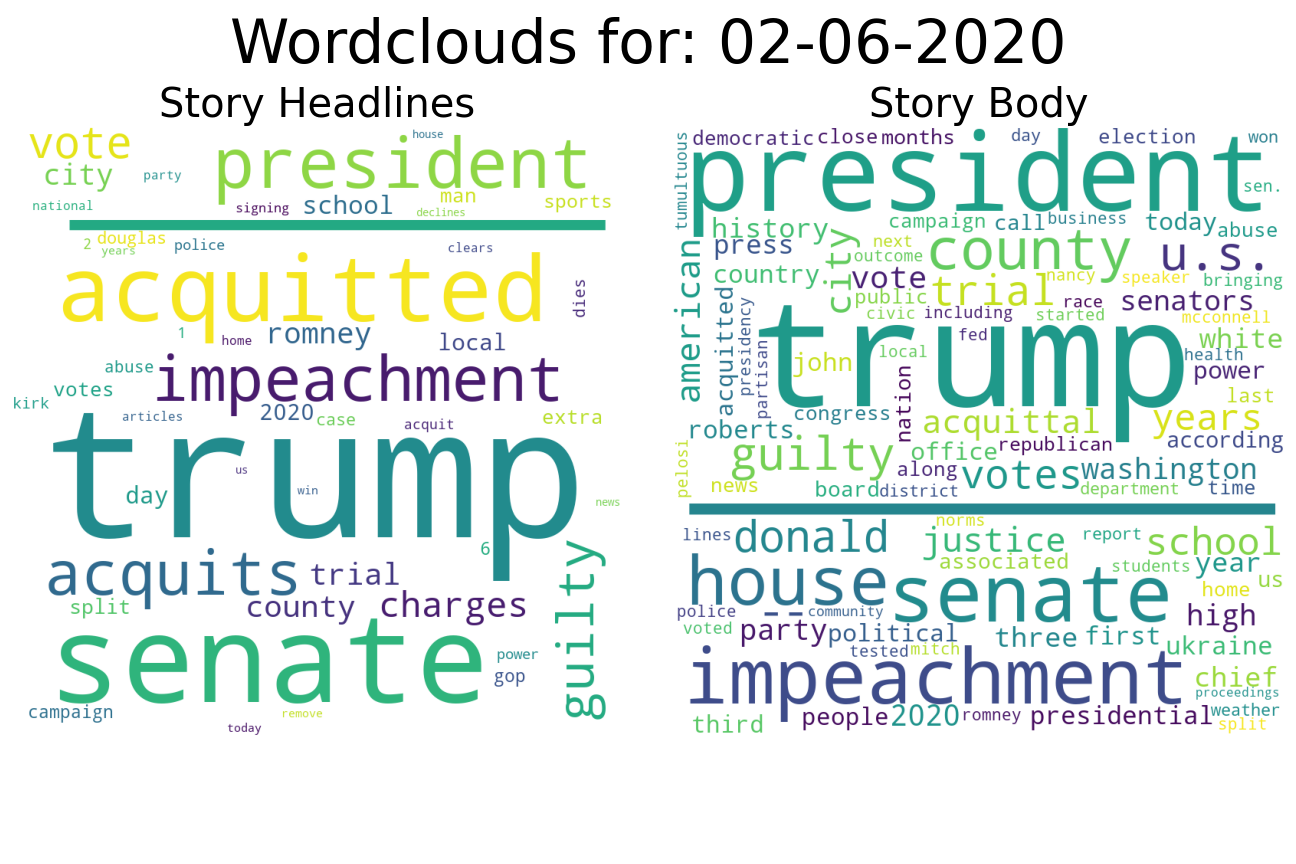 I’m also continuing all the
I’m also continuing all the